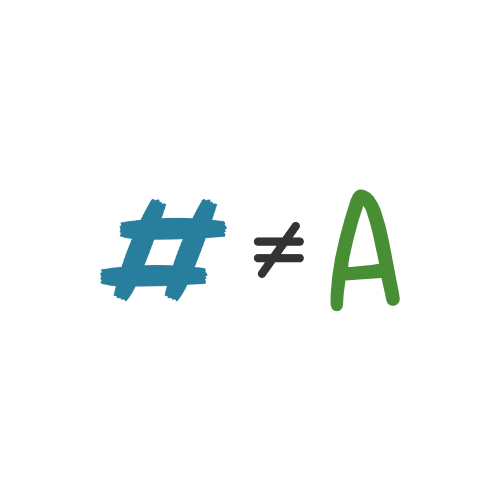






# Variable Type Check - Base R
actual_number <- 2022
fake_number <- "2022"
#Actual Number?
is.numeric(actual_number)[1] TRUE[1] FALSE“With The pointblank Package”
Cleveland R User Group
October 26th 2022 | 2022-10-26

I’m ABSOLUTELY not an expert in Data Validation or the pointblank package

Why is it important? … Because…

.
The art of Data Validation is a Rabbit Hole
Don’t fall for the “Validation Crux”
“Is this variable the same class/type we are expecting?”
Example: - Is R reading this as a numeric or integer variable, or is it just a string impostor?
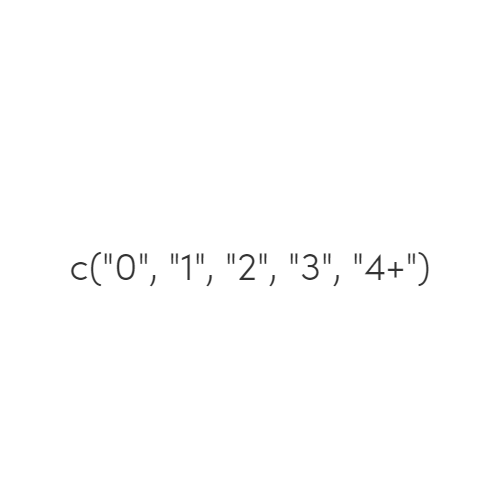
“Is the value of the variable one that is allowed or expected?”
Example: - Can we confirm that the value R is reading makes sense given the context of allowed or expected values for this variable?
“Is there any missing data where there should/shouldn’t be?”
Example: - Do we logically expect any values in a variable to be missing or should missing data prompt us to investigate the data further?
“Is the data logically making sense upon delivery or after transformation/analyses/processing?”
Example: - Does the data make sense given the context of collection, processing, or analysis?
“Should we expect data values to be unique or duplicated?”
Example: - Given the context of the data, do we expect R to find any duplicates? Is it a bad thing or have any meaning if present?
“Is the string/character value of the right left given the context of the data?”
Example: - Is the string’s length appropriate given the data’s meaning?
“Is the general format of the data as we expect?”
Example: - Can R confirm that our data matches a specific format that is needed for our work?
“Does the data fall into an accepted pre-determined range?”
Example: - Can R confirm that our data matches a specific range that fits within the context of the data?
pointblank?
Pointblank is an R package by Rich Iannone (author/maintainer) and Mauricio Vargas (author) that was created to assist with methodically validating data and keeping track of relevant metadata (data about data) in R.
pointblank?pointblank Use-Cases: Data Quality Reporting

pointblank Use-Cases: Data Quality Reporting
pointblank Use-Cases: Data Quality Reporting
pointblank Use-Cases: Data Quality Reportingpointblank Use-Cases: Data Quality Reporting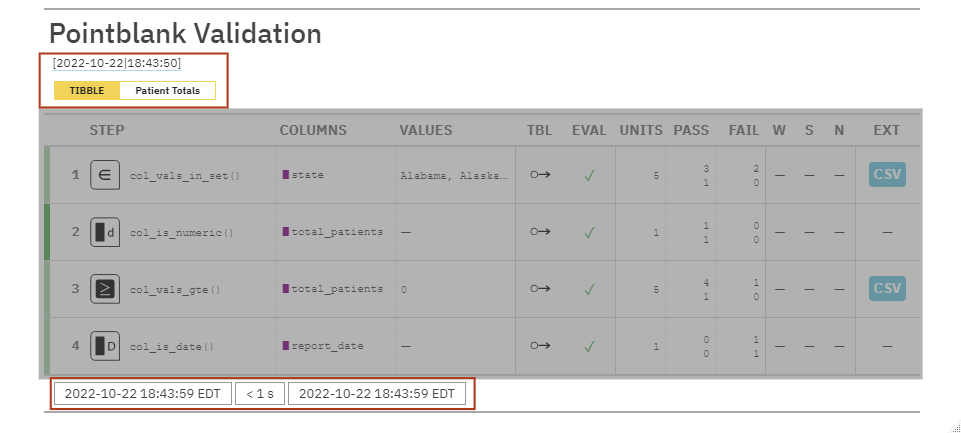
pointblank Use-Cases: Data Quality Reporting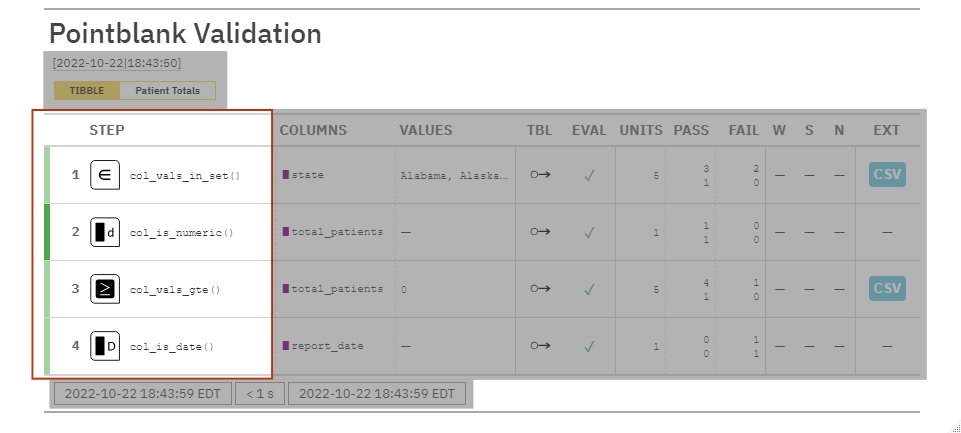
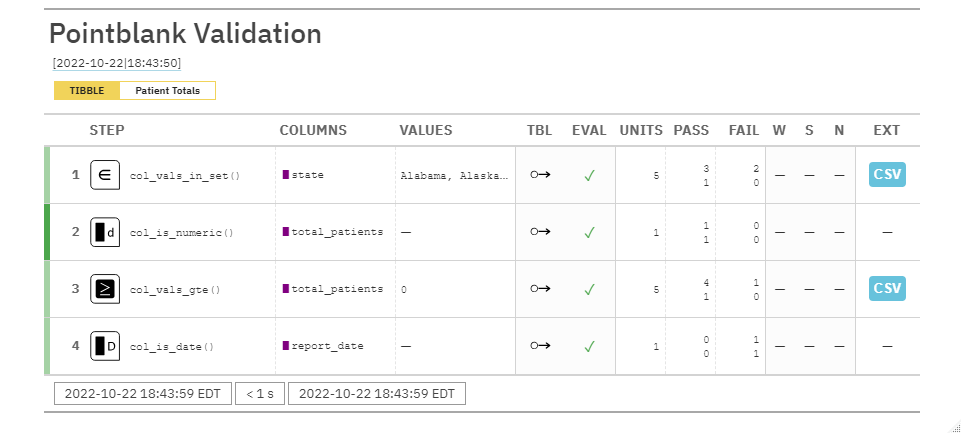
STEP: The name of the validation functions used. Color-coded tabs let us know if a step was completed. Darker green means everything in the step passed
pointblank Use-Cases: Data Quality Reporting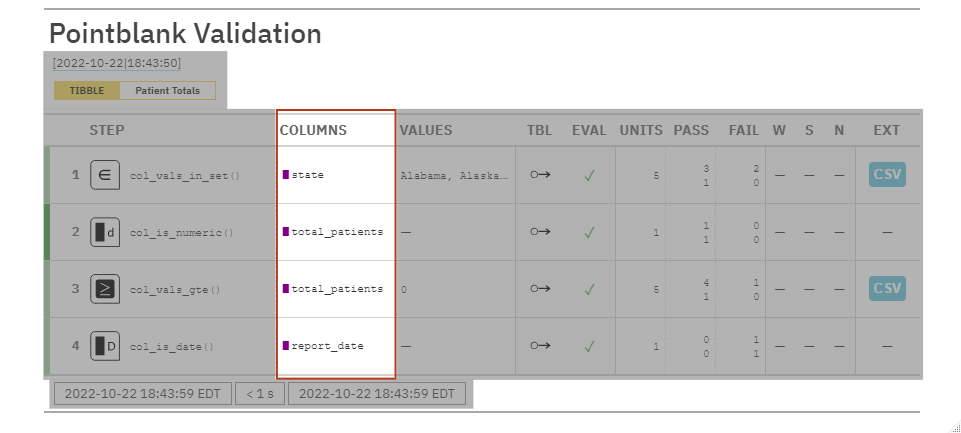
COLUMNS: The target columns we told the agent to interrogate via our validation rules
pointblank Use-Cases: Data Quality Reporting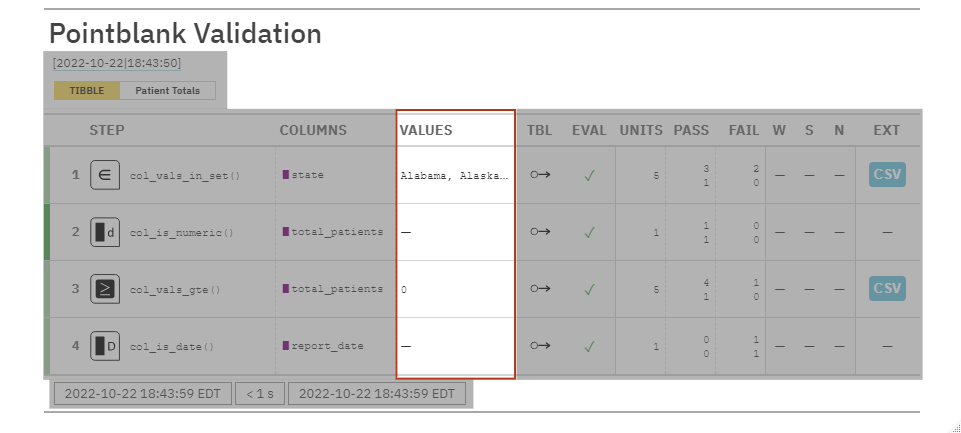
VALUES: Any required values needed/used to test for validation if applicable.
pointblank Use-Cases: Data Quality Reporting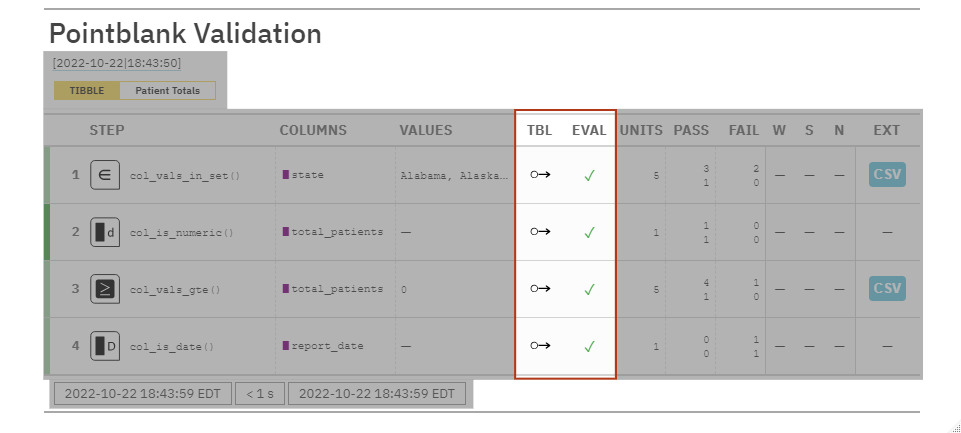
TBL: Let’s us know if the table was mutated in a validation step. EVAL: Let’s us know if there’s issues R might have evaluating the table itself.
pointblank Use-Cases: Data Quality Reporting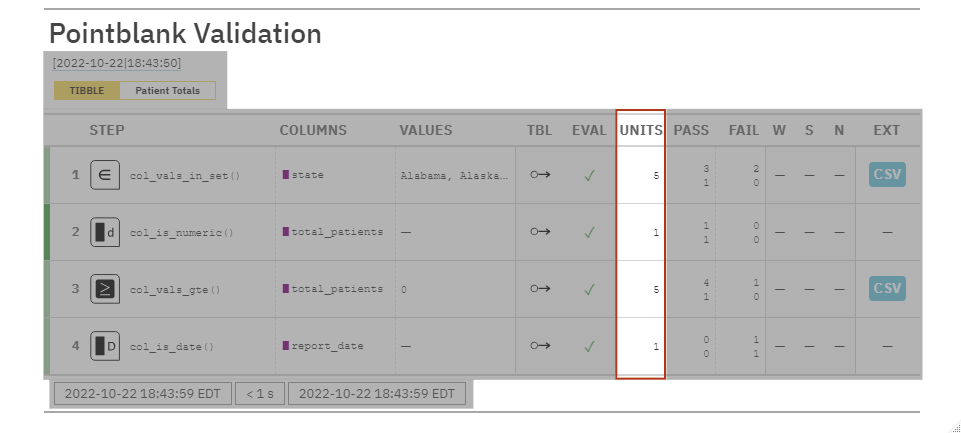
UNITS: Gives the total number of tests ran for each step
Steps that check all values in a column = 5 because we have five rows of data
Steps that just check a whole column = 1 because it’s just evaluating one column
pointblank Use-Cases: Data Quality Reporting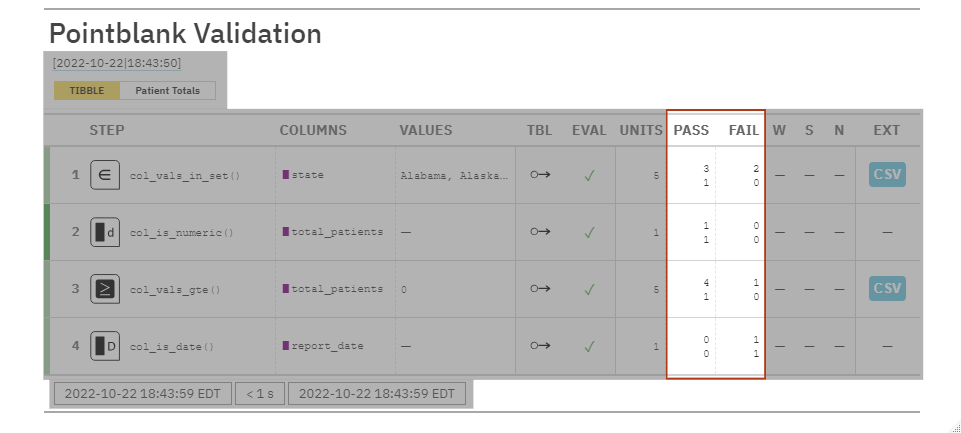
PASS/FAIL: Gives the number/percentage of passing and failing unit tests
pointblank Use-Cases: Data Quality Reporting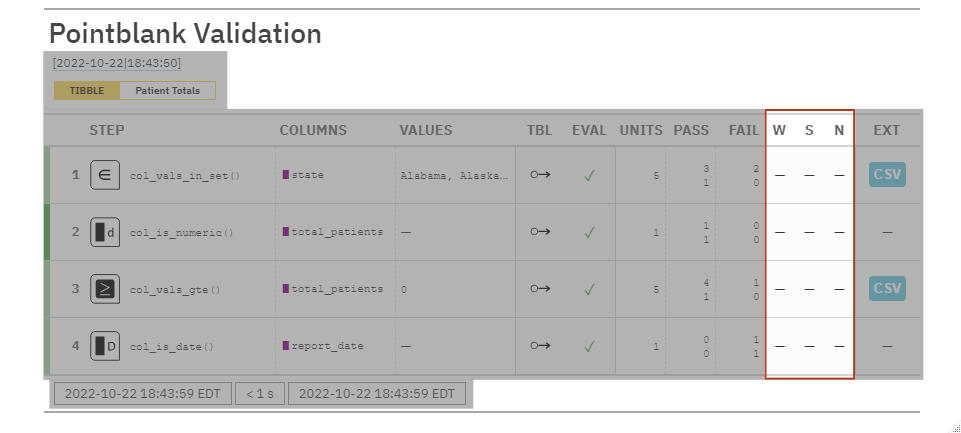
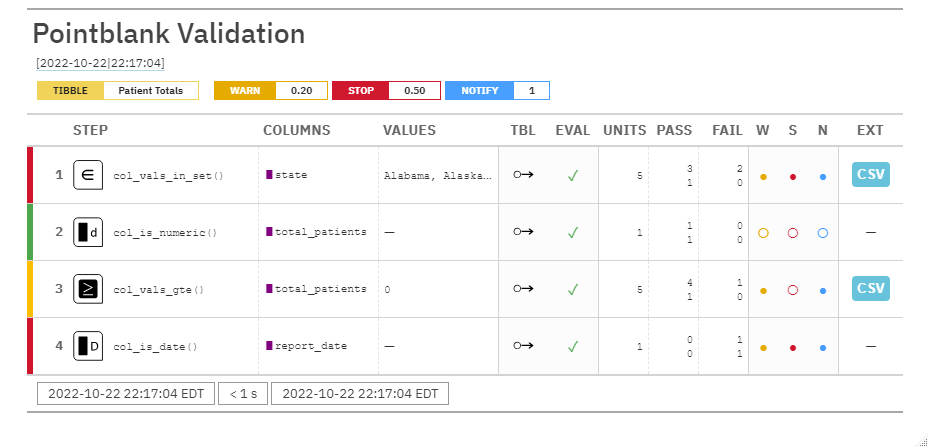
W,S,N: Tells us if the validation steps have entered WARN, STOP, or NOTIFY. This is empty because there’s no action levels set.
pointblank Use-Cases: Data Quality Reporting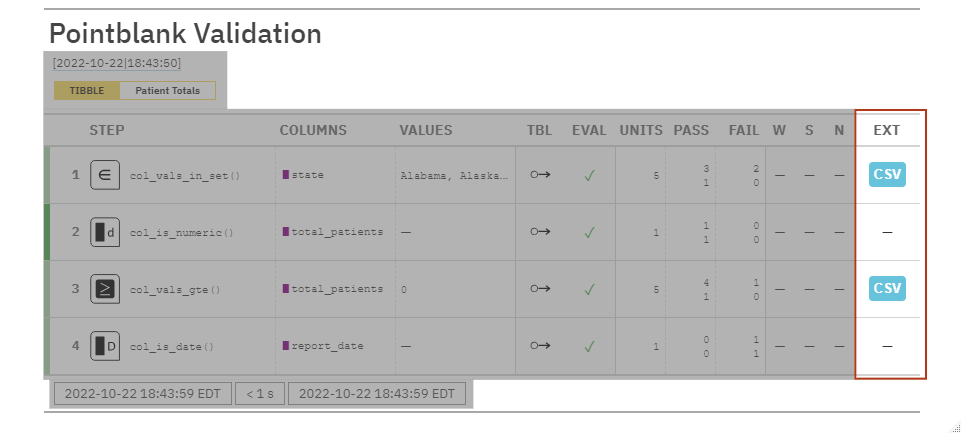
EXT: Provides a download of a data extract of observations that failed any validations if applicable.
pointblank Use-Cases: Data Quality Reportingaction_levels()) in Viewer Pane:pointblank Use-Cases: Pipeline Data Validation
pointblank Use-Cases: Pipeline Data Validation
pointblank Use-Cases: Pipeline Data Validation
pointblank Use-Cases: Table Scans